Dieser Beitrag basiert auf einem Einführungsvortrag zum Thema Dubletten / Duplikate im Civi-Stammtisch am 10. Oktober 2024.
Es ist eine Zusammenfassung des Kapitels „Eliminating duplicates“ aus dem englischsprachigen Buch „Using CiviCRM“ von Erik Hommel, Joseph Murray, Brian P. Shaughnessy in der zweiten Auflage, erschienen bei Packt Publishing (mittlerweile ist das E-Book für 8,99 Euro (9,99 Euro im Warenkorb) erhältlich (Stand Oktober 2024)) - ergänzt durch eigene Erfahrungen der Beitragsverfasserin.
Einleitung
Data is king. Even the most advanced CRM tools will be virtually useless if the data it is handling is incorrect, messy, or outdated. Your system will live or die based on the principle of garbage in/garbage out.
Damit beginnen die Autoren ihr Kapitel zum Thema Duplikate in CiviCRM.
Ein wichtiger Schritt auf dem Weg zu Qualität und Zuverlässigkeit der eigenen Daten ist also die Reduktion von Duplikaten. Dubletten sind allerdings fast unvermeidlich, insbesondere wenn wir Nutzer:innen ermöglich, ihre Daten selbst durch Formulare an uns und unser CiviCRM zu übermitteln.
Erfreulicherweise liefert CiviCRM ein paar Lösungen mit, die uns diese Arbeit erleichtern - zudem gibt es Erweiterungen, die der Entstehung von Dubletten vorbeugen und bei der Bereinigung helfen.
Strategien
- Regeln und Prozesse
Es ist empfohlen, Regeln und Prozesse festzusetzen, an die sich die Menschen, die mit dem System arbeiten, halten. So sollten alle, die einen Kontakt neu eingeben oder bearbeiten wollen, vorher den Namen in die Suche eingeben. So geht man sicher, dass es den Kontakt nicht schon gibt, vielleicht entdeckt man auch dabei, dass es bereits Dubletten gibt und kann sich direkt um die Bereinigung kümmern. Hier geht es um den menschlichen Einsatz der Organisation für das System.
Eigene Erfahrung:
Ich bin in der zweiten Organisation beschäftigt, die CiviCRM nutzt. In der ersten Organisation wurde regelmäßig nach Veranstaltungen, zu denen Besucher:innen sich online anmelden können, nach Duplikaten gesucht und diese zusammengeführt.
In der Organisation, in der ich nun arbeite, galt lange die policy, kein automatisches Matching zu nutzen, sondern jeden Kontakt über ein Formular neu anzulegen. Nur eine Hand voll Mitarbeitende gaben Kontakte ein und kümmerten sich um die Datenpflege sowie die Bereinigung.
Nun ist die Organisation stark gewachsen und es gibt ca. 50 aktive Online-Formulare. Es entstehen so viele Duplikate in den unterschiedlichsten Kontexten, dass eine manuelle Bereinigung kaum mehr möglich ist - zumal es einen größeren Rückstau gibt.
Menschlicher Einsatz bedeutet für mich:
Jede:r sollte aktiv sein und Dubletten nicht ignorieren, wenn man auf die stößt.
Jede:r sollte Dubletten der Projektleitung (des CiviCRM) oder an Kolleg:in melden - ggf. selbst handeln, wenn man sich inhaltlich sicher ist, wie das Matching aussieht.
-
Beim Erstellen (Inline deduping)
CiviCRM liefert eine eingebaute Suche nach Duplikaten beim Anlegen eines Kontakts mit. Die Dublettensuche basiert auf der supervised / beaufsichtigt-Matching-Regel. Aber: die Duplikatsregeln sind ein Sicherheitsnetz, das durchaus Löcher hat. Wenn uns bei der Eingabe Informationen fehlen oder wir andere Daten haben, als die Matching-Regeln benötigt, kann es zu Fehlern kommen (also nie komplett auf dieses Tool verlassen). So könnte die Matching-Regel zum Beispiel auf Vorname, Nachname und E-Mail-Adresse hin prüfen. Wenn ich aber Vorname, Nachname und Postadresse eingeben, könnte die Person nicht als bereits vorhandene Person erkannt werden. -
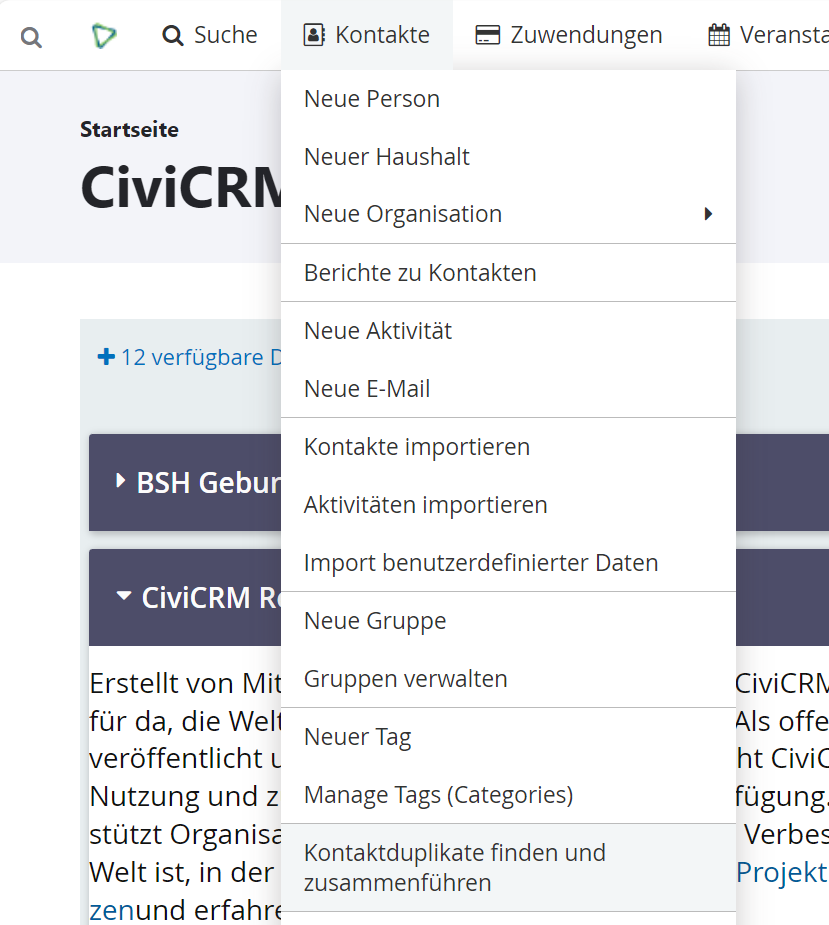
Kontaktduplikate finden und zusammenführen
CiviCRM bietet uns die gezielte Suche nach Duplikaten. Du findest diese unter Kontakt --› Kontaktduplikate finden und zusammenführen.
Es empfiehlt sich, diese Suche regelmäßig laufen zu lassen und die Ergebnisse zu bereinigen. Je nach Größe der Organisation und Aufkommen von Dateneingaben (besonders der von außen durch Formulare) kann diese Routine wöchentlich, monatlich oder halbjährlich erfolgen. Dies folgt dem Prinzip: Je mehr Eingaben, desto häufiger die Suche und Bereinigung.
Für die Suche wählt man die Kontaktart und dann eine konfigurierte Regel für das beaufsichtigte Matching aus und lässt sie für diese Auswahl laufen.
Eigene Erfahrung:
In unserer Organisation brauchen wir wieder eine stärkere Regelmäßigkeit und die Mithilfe aller Mitarbeitenden - jede:r muss in der Lage sein, fundiert entscheiden zu können, ob man matcht (und wie / was) oder in den Austausch mit Kolleg:in geht oder besser nicht matcht.
Und: Ich möchte das automatischen matching implementieren, damit der Großteil der Dubletten gar nicht erst entsteht.
Zusätzlich müssen die Kolleg:innen stärker geschult werden, damit die oben angesprochene fundierte Entscheidung getroffen werden kann und sie sensibilisiert sind für das Thema Dubletten.
Regeln für Duplikats-Suche
Für jede Kontaktart (Person / Haushalt / Organisation) lassen sich mehrere Regeln konfigurieren. Für die oben genannte Duplikats-Suche wählt man die Regel für beaufsichtigtes Matching aus. Für die Inline-Duplikatssuche beim Anlegen von Kontakten wird ebenfalls die Regel für beaufsichtigtes Matching verwendet. In beiden Fällen kann die Regeln etwas lockerer sein, da eine Person hier beim Zusammenführen von Duplikaten bzw. Erkennen von Duplikaten eine fundierte Entscheidung trifft.
Die Regeln für unbeaufsichtigtes Matching wird bei automatischem Matching verwendet, wenn kein Mensch, sondern das System die Entscheidung trifft, ob es sich um ein Duplikat handelt. Dies ist die wichtigste Matching-Regel und sie sollte strikter sein und ein engeres Netz bilden, damit keine falsch positiven Matches / Zusammenführungen entstehen. Falsche Zusammenführungen sind in der Regel weitaus schwerer zu korrigieren, als die manuelle Zusammenführung zu übernehmen. Erst mal muss jemand merken, dass es diese fälschliche Zusammenführung gibt, die Informationen im Kontakt dann wieder richtig zuzuordnen und zwei Kontakte wieder in den ursprünglichen Zustand zu bringen, ist nach meiner Erfahrung nahezu unmöglich.
Dann gibt es noch die allgemeine Regel - wofür die verwendet wird, weiß ich leider nicht.
Im System lassen sich außerdem Ausnahmen bilden, man kann zwei Kontakte damit „als kein Duplikat“ markieren (whitelisten). Diese beiden werden einem dann nicht wieder als mögliches Duplikat angeboten. Die Ausnahmen lassen sich auch wieder auflösen.
Matching-Regeln: Aufbau / Erstellung
Bei der Konfiguration der Regeln gibt es folgende Möglichkeiten:
Verwendungen: unbeaufsichtigt, beaufsichtigt und allgemein
Feld: dabei wählt man das Feld, auf die die Regel matchen soll, so wie Vorname, Nachname. E-Mail-Adresse…
Länge: Anzahl der Zeichen, die übereinstimmen sollen, Beispiel: Johnson und Johnsten, bei 4 Zeichen (J O H N) ergibt sich ein Match, bei 6 Zeichen nicht (nach 5 Zeichen folgt bei dem einen Namen ein O, beim anderen ein T)
Lässt man „Länge“ leer, müssen alle Zeichen übereinstimmen
Achtung: eine Länge zu setzen, führt ggf. zu Performanceproblemen und mehr Ergebnissen.
Gewichtung: je nach Schwellenwert und wie viele Felder übereinstimmen, wird ein Match erkannt - es ist die Berechnung der Wahrscheinlichkeit einer Übereinstimmung, Beispiel (Feld (Gewichtung) + Feld (Gewichtung) = Schwellenwert)
Vorname (1) + Nachname (1) = 2 --› beides muss matchen
Vorname (2) + Nachname (2) + E-Mail (1) + Ort (1) = 5 --› Vorname und Nachname sowie E-Mail ODER Ort müssen matchen, um den Schwellenwert 5 für ein Match zu erreichen.
Wichtig: Diese Regeln sorgfältig durchdenken! Denn:
zu strenge Regeln = wirkliche Duplikate werden übersehen
zu unscharfe / lockere Regeln = lange Ergebnislisten, die schwer zu bearbeiten sind
Regel anwenden
Bei der Duplikatssuche kann die ganze Datenbank oder eine bestimmte Gruppe durchsucht werden. Die Ergebnisliste zeigt erst die Paarung mit höherer Gewichtung.
Wählt man bei einem möglichen Duplikat „vereinigen“, werden beide Kontakt gegenüber gestellt. Wenn das Paar zusammengeführt wird, wird der Kontakt auf der linken Seite gelöscht.
Achtung: es ist ein kraftvolles Tool!
Geht etwas schief, bleibt noch der Papierkorb, wenn er denn aktiviert ist, ansonsten ist der Kontakt weg - aber man sollte sich nicht darauf als Sicherheitsnetz verlassen.
Erweiterungen
Bei unserem Stammtisch stellte Lena von Systopia folgende Erweiterungen vor, die ich hier ganz kurz nennen möchte - die Stichworte entsprechen meinen Notizen und sind ohne Gewähr:
X-Dedupe
- erweiterte Deduplizierung
- bietet verschiedene Modultypen: Suche, Filter, Konfliktlösendes Modul, Custom module
Wenn installiert, erreichbar unter Dokumentation --› Kontakte zusammenführen, Konfiguration unter Admin --› Automation --› erweiterte dedupe
Hier findest du die Erweiterung:
X-Dedupe (Extended Deduplication) | CiviCRM
Introduction - X-Dedupe - CiviCRM Documentation
GitHub - systopia/de.systopia.xdedupe: CiviCRM Extended Dedupe Tools
XCM
- Onlineintegration, CiviBanking
- mehrstufige Logik
- Konfigurationsmöglichkeiten
- Konfiguration zum Umgang mit geänderten Daten pro Feld
- gematchte und neue zu Gruppen oder mit tag markiert
- Kontaktimport
Wenn installiert, Konfiguration unter Admin --› Automation --› XCM
Hier findest du die Erweiterung:
Extended Contact Matcher (XCM) | CiviCRM
Introduction - Extended Contact Matcher (XCM) - CiviCRM Documentation
GitHub - systopia/de.systopia.xcm: CiviCRM Extended Contact Matcher
Deduper extension
Bei der Recherche fand ich in der Installations-Oberfläche in CiviCRM noch diese Erweiterung, die ich mich anschauen werde.
Hier findest du die Erweiterung:
Home - Deduper - CiviCRM Documentation
GitHub - eileenmcnaughton/deduper
Abschluss
Dubletten können ein Riesenhindernis bei der effizienten Nutzung von CiviCRM darstellen und Analysen und Prozesse erheblich behindern. Deshalb sind die Verhinderung sowie die Bereinigung von Dubletten sehr wichtig.
Ich werde mich tiefgehender mit den genannten Erweiterungen beschäftigen und freue mich, wenn auch ihr hier unter dem Beitrag eure Erfahrungen und Fragen mit der Community teilt.